Python
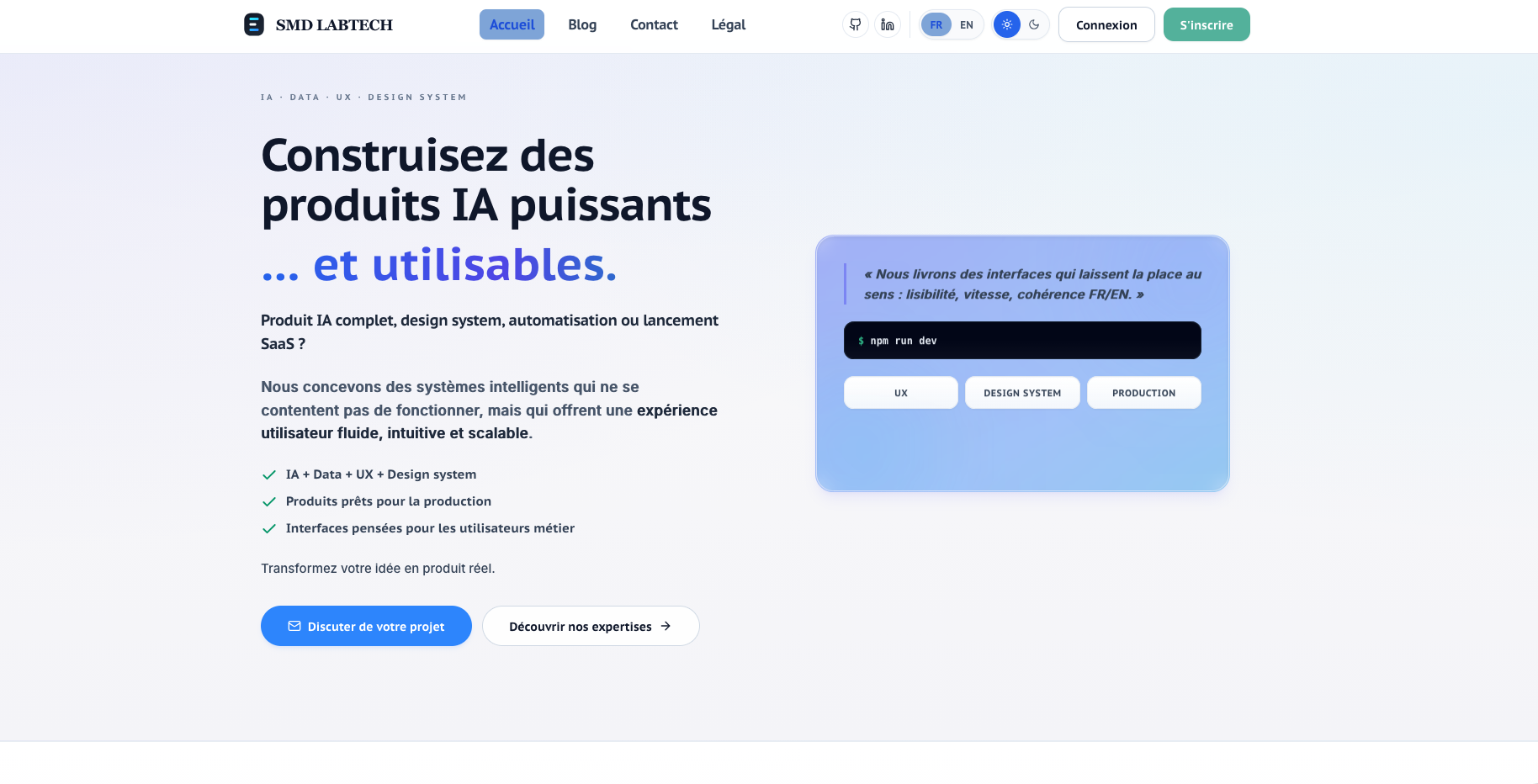
Nous concevons et déployons des systèmes d’intelligence artificielle capables de passer du prototype à la production.
Au-delà des POCs, nous construisons des systèmes intelligents scalables, orchestrés et industrialisés, intégrés aux workflows métiers.

Au fil des projets, une conviction s’est imposée : en data, l’important n’est pas la technologie choisie, mais l’impact de la solution apportée.
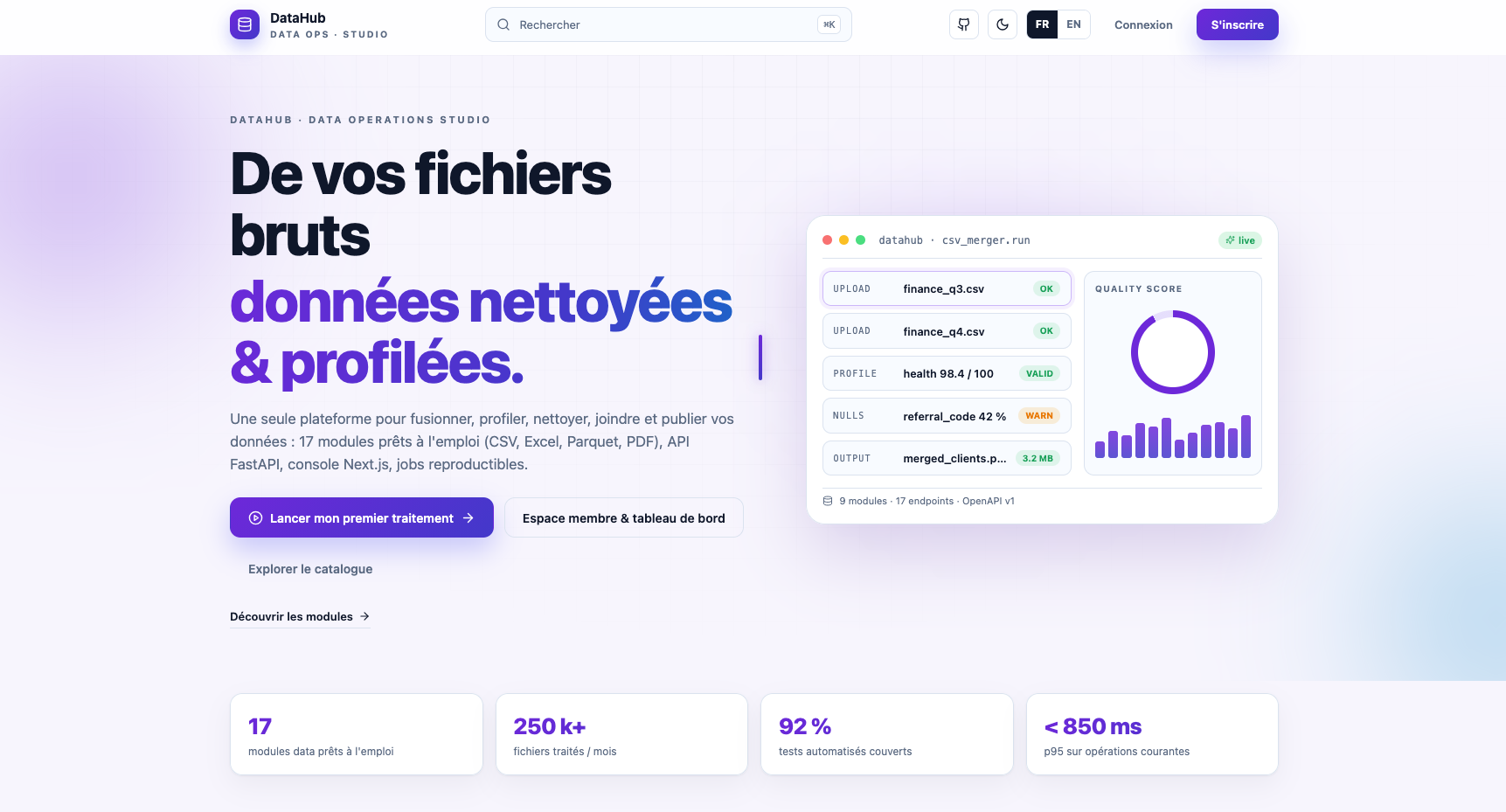
Pipelines SQL et Python, BigQuery, modélisation et intégration SAP / datalakes, automatisation, qualité des données et industrialisation (CI/CD, conteneurs).
Missions de conseil en finance, marketing data et direction comptable — retail, automobile, télécom, aviation.
Vertex AI et BigQuery ML, LLM / RAG et agents orchestrés, Power BI, Streamlit et APIs — de l’expérimentation au livrable exploitable par les métiers.
Python

Google Cloud
Power BI

Streamlit
PARTENAIRES
Notre expérience en environnements de conseil, data et transformation — notamment avec Axys, Carrefour, Škoda France, La Poste, SNCF Réseau et Air France.

SNCF Réseau

Air France

Axys

Carrefour

Škoda France

La Poste
Trois leviers concrets — du cadrage à la mise en production, avec une exigence forte de clarté métier.
Pipelines, entrepôts, qualité et intégration SAP / S/4HANA sur GCP — livrables exploitables par les équipes.
Vertex AI, BigQuery ML, scoring et restitution Power BI / Looker orientées décision.
Conteneurs, observabilité, garde-fous et itérations courtes pour sécuriser les mises en production.
PARCOURS
Des projets construits à partir d’expériences terrain en Data & IA : SQL, Python, Cloud, automatisation et industrialisation de solutions à l’échelle.
Missions autour de SNCF Réseau et Air France : volumétries élevées, indicateurs opérationnels, exigences de qualité et de traçabilité des données.
Contexte Carrefour — analyse de données retail et collaboration avec les équipes métiers sur la performance et les usages.
Škoda France — données commerciales et restitution pour les équipes terrain et la direction.
La Poste — projets orientés données opérationnelles et performance de service.
Axys et paysages data hétérogènes — cadrage, intégration et livrables orientés décision.
LABS & OPEN SOURCE
Prolongement concret du parcours décrit à propos : démos hébergées (GCP / Cloud Run), prototypes et dépôts GitHub publics — au croisement des missions retail, transport, aviation et télécom détaillées dans le profil.
Aucune plateforme ne correspond à cette recherche.
Technologies et outils que nous utilisons souvent — non exhaustif, aligné sur les projets et le CV (badges Shields.io).